AI를 사용하여 AI 생성 이미지를 결정하는 것은 생각보다 쉽지 않습니다. 이 논문는 지난 11월 CVPR에 게재된 논문으로, 이전 논문에서 제시한 방법의 효율성을 검토하는 리뷰 논문에 가깝습니다. 레코드 및 코드 공식으로 주어진이 작업을 기반으로 추가 방법을 조사하고 구현해야 합니다.
0. 요약
지난 10년 동안 거위그리고 최근 확산 모델이러한 방법에 의한 합성 매체의 생산에서 상당한 발전이 이루어졌습니다. DM은 Text-to-Visual(TTV) 생성을 가능하게 합니다. 악의적인 공격이 연구는 DM에 의해 만들어졌습니다. 합성 이미지와 실제 이미지를 구별하는 것이 얼마나 어려운지 소셜 네트워크에서 이미지 압축 및 크기 조정을 사용하여 어려운 시나리오를 이해하고 이해합니다. 작업에 대한 현재 감지기의 적합성 평가할 목표
1. 소개

DM을 활용한 합성매체는 사실적이어서 활용도가 높지만 남용되기 쉽다. 이를 방지하기 위해 다양한 연구 방법이 개발되었습니다.
- 이미지의 그림자 또는 반사 사진의 비대칭찾는 방법
- 그 이후로 대비와 빛과 같은 전역적 의미 불일치를 찾는 방법이 개발되었습니다.
- 그러나 GAN과 DM의 발달로 모순점을 찾기 어렵다.
- 최신 SOTA 감지기 인간의 눈으로 볼 수 없는 영역조사했다
- 합성 시각 데이터는 다음에 생성됩니다. 반드시 공간 도메인에 고유한 추적왼쪽
- 각 세대 아키텍처에는 서로 다른 고유한 흔적이 있습니다.
- 또한 업샘플링 과정에서 GAN f주파수 영역의 특정 스펙트럼 피크왼쪽
그러나 StyleGAN3과 같은 정교한 아키텍처의 출현으로 SOTA 감지기는 추적도 감지할 수 있습니다. 찾기 힘들다 +트랙이 너무 안좋아서 사진에 조금밖에 없네요 손상된(크기 조정 등), 성능에 영향을 미칩니다.
NVIDIA의 StyleGAN3 이미지를 결정하기 위한 최근(2022년) 경쟁에서 긍정적인 결과가 나왔지만 이는 이상적인 환경에서 테스트되었습니다. 이 연구 DM 생성 이미지의 아티팩트가 GAN과 동일한지, 현재 SOTA 디텍터가 어느 정도 효과적인지, 어떤 이미지에 적용되는지 알아보기 위해 하는 것이 목적입니다.
2. 배경
합성영상의 차별화에 관한 중요한 연구결과 발표
-
증가수업 다양한 기차 기록모델의 견고성을 높입니다. 하지만 크기 변경 빌드 단계에서 생성된 고주파 트레이스를 제거하기 때문에 피하다. 이에 대한 방법이 있습니다.
- 크기 조정 없이 로컬 패치 단위를 잘라내어 학습
- Fusion 사용 시 전체 이미지를 보고 최종 판단
- 첫 번째 레이어에서 다운샘플링 방지
-
로컬 패치에 집중하면서 로컬-글로벌 컨텍스트를 유지하는 것이 중요합니다.
-
대규모 데이터 세트에 대한 사전 교육이 중요하지만 원본 이미지 대신 나머지(중요하지 않은 이미지…?) 교육이나 너무 많은 증강은 도움이 되지 않았습니다.
3. 유물 분석
GAN 제품은 아키텍처(계층의 유형 및 수)에 따라 다릅니다. 고유한 흔적(지문)남아있다. 지문은 파이프라인을 통과하여 어떤 GAN인지 알아냅니다. PRNU 패턴 추출BE.
PRNU 패턴: 광 응답 비균일성 패턴.
빛이 있을 때 픽셀마다 다른 게인으로 발생하는 FPN(Fixed Pattern Noise)
- 사진은 노이즈 감소 필터 $f(\cdot)$를 통과합니다.
$$
\hat{X_i} = 에프(X_i)
$$
- 원본 이미지에서 제거 잔여 소음찾았다
$$
R_i = \hat{X_i} – f(X_i)
$$
- 잔차의 평균내 지문을 얻었다
$$
\hat{F}=(1/N)\Sigma_{i=1}^{\hat{N}}R_i
$$

본 연구에서는 1000개의 이미지로부터 잔차를 평균한 후, 푸리에 변환사용.
GAN 모델은 강력한 정점을 공유합니다.나타납니다. GLIDE, Latent Diffusion 및 Stable Diffusion과 같은 DM 모델도 공통 지문을 보여 동일한 검출기가 효과적인 것처럼 보이지만 다른 DM 모델은 피크를 많이 나타내지 않습니다.
4. 인식 성능
- 테스트 개체
- GAN: ProGAN, StyleGAN2, StyleGAN3, BigGAN, EG3D
- 트랜스포머: 길들이기 트랜스포머, DALL-E Mini, DALL-E 2, GLIDE
- 확산 모델: 잠재 확산, 안정 확산, ADM(Ablated 확산 모델)
- TTI용 COCO 음성 프롬프트
- 실제 데이터: COCO, ImageNet, UCID
- 기차
- 362,000개의 ProGAN 이미지, 20개 카테고리
- 200,000개의 잠재 확산 이미지, 5개 카테고리
- 시험
- 모델별 합성 이미지 1000개 + 실제 이미지 5000개
-
탐지기
- 사양: 주파수 분석
- PatchForensics: 로컬 패치 분석
- Wang2020: 흐림 및 압축 확장 기능이 있는 Resnet50
- Grag2021: Wang2020 백본이지만 첫 번째 레이어에서 다운샘플링을 피하고 집중적인 증강
-
평가 방법
- AUC, acc 임계값 = 0.5
일반화 및 견고성
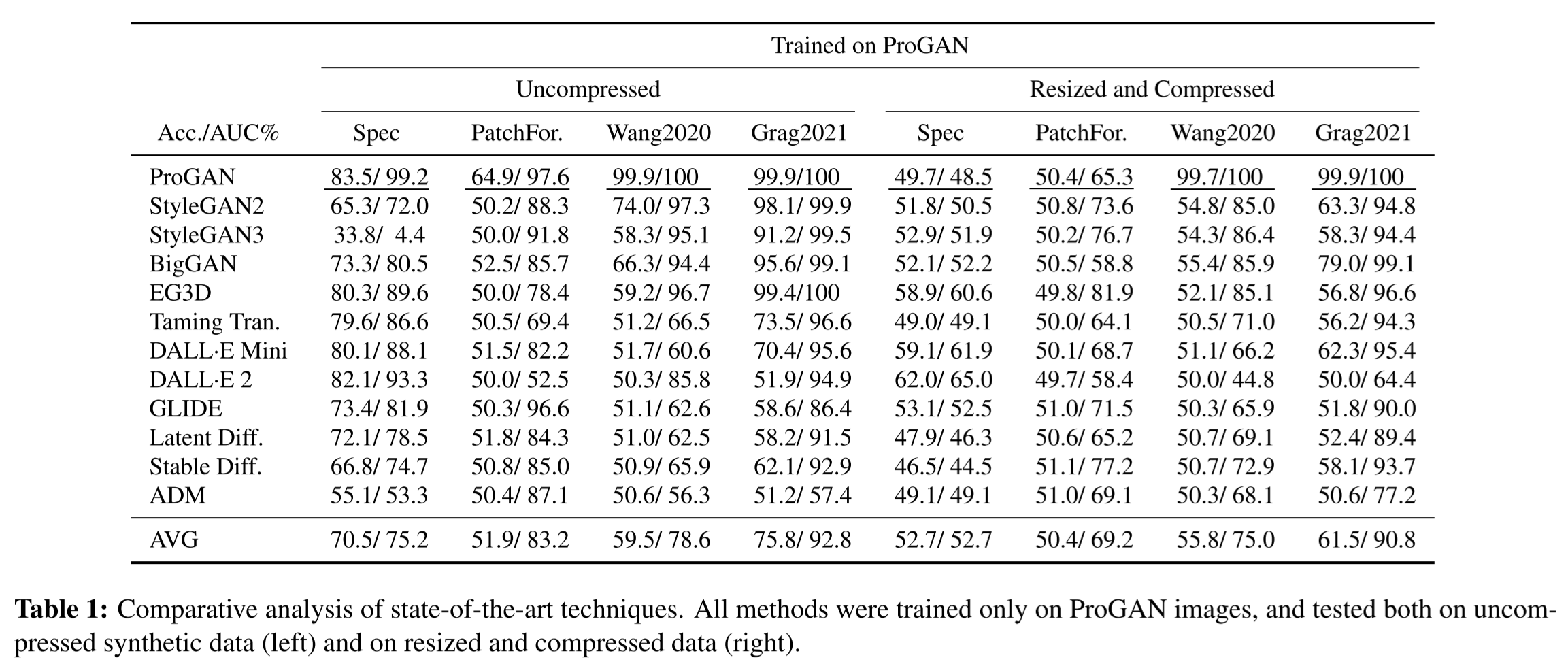
-
PNG 형식 압축되지 않은 합성 이미지실험하다
- 실제 이미지는 항상 압축된 JPEG이므로 흔적이 남습니다. 구별하기 쉬운 성능 향상
- 하지만 열차의 Acc 임계값이 다른 데이터셋에서 문제가 되어서 성능이 나오지 않는 경우가 있습니다.
-
IEEE VIP 컵에서 사용 실제 환경본뜨다
- 시험마다 임의 위치, 크롭 크기200×200 리사이징 후 JPEG factor 65~100 압박 붕대
- 대부분의 경우에 성능 저하특히 스파이크가 약한 DALL-E 2 및 ADM에서.
- 가장 성능이 좋은 Grag2021을 ADM 이미지로 학습시켜 실험
- 성능은 ADM뿐만 아니라 유사한 아티팩트로 안정적인 확산에도 매우 좋습니다.
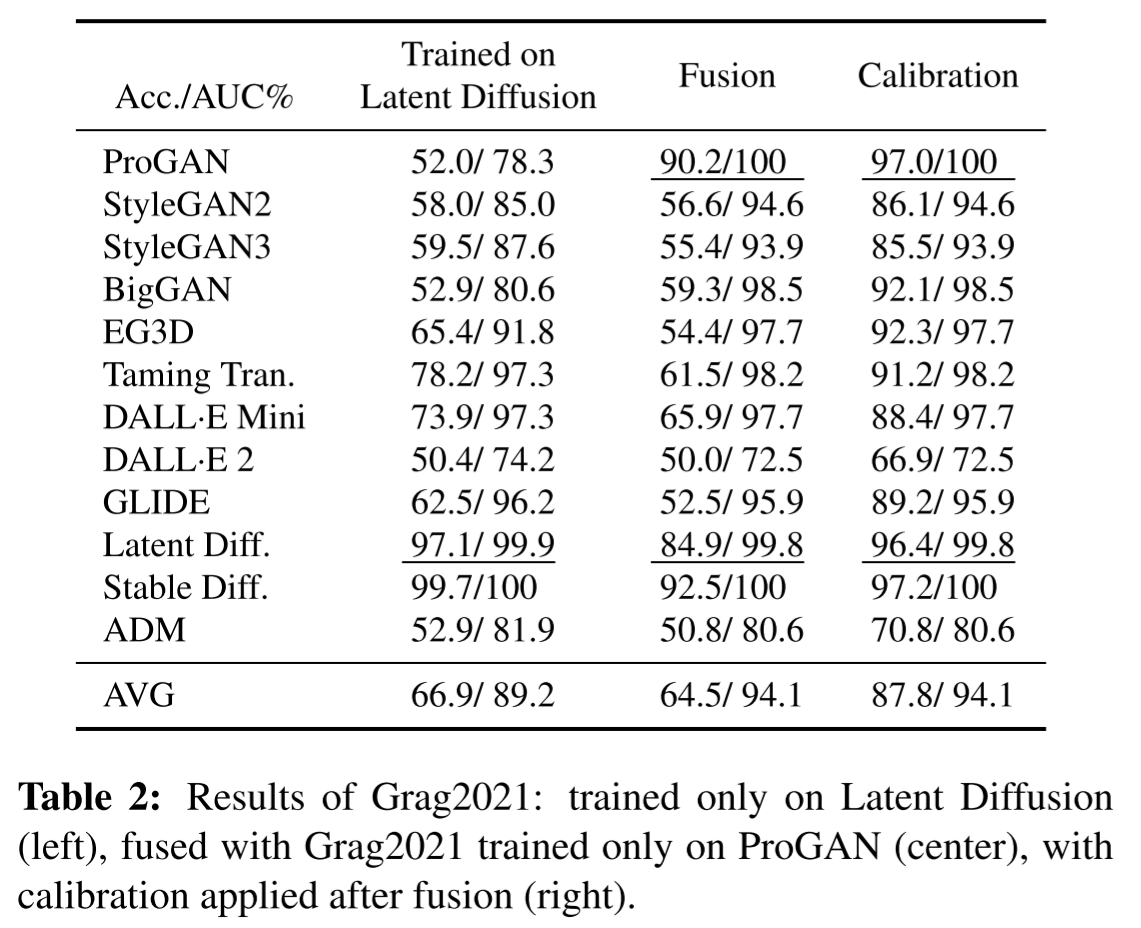
융합 및 교정
-
Latent Diffusion과 ProGAN으로 Grag2021을 학습한 결과 융합(단순 평균)GAN 성능은 향상되었지만 DM의 정확도는 여전히 낮았습니다.
-
Platt 스케일링 방법으로 구경 측정 법원 청문회
- 플랫 스케일링 방법 : 로지스틱 회귀에서 모델의 결과를 다시 태워서 값을 계산
- 성능은 올라갔지만 여전히 기차에서 나오지 않은 아티팩트가 있는 이미지를 찾을 수 없었습니다.
5. 결론
이 연구 확산 모델에 의해 생성된 합성 이미지 인식DM 이미지는 **고유한 지문입니다.(아티팩트/추적), 그러나 SOTA** 탐지기 성능은 특정 모델 및 포렌식 추적에 크게 의존합니다.일반화는 여전히 어렵고 DM 이미지 인식 문제를 해결하기 위해 추가 분석이 필요하다는 것을 발견했습니다.